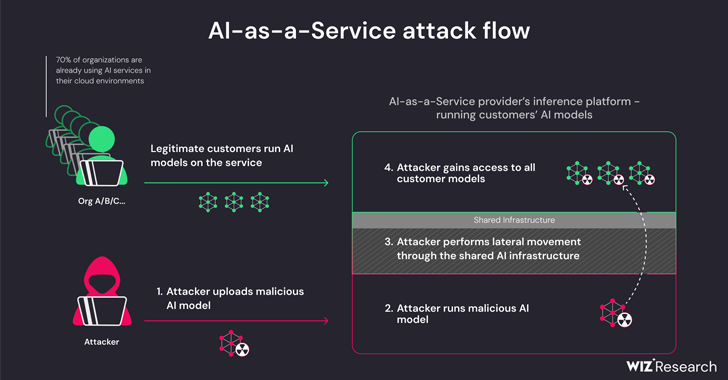
New research has found that artificial intelligence (AI)-as-a-service providers such as Hugging Face are susceptible to two critical risks that could allow threat actors to escalate privileges, gain cross-tenant access to other customers’ models, and even take over the continuous integration and continuous deployment (CI/CD) pipelines.
“Malicious models represent a major risk to AI systems, especially for AI-as-a-service providers because potential attackers may leverage these models to perform cross-tenant attacks,” Wiz researchers Shir Tamari and Sagi Tzadik said.
“The potential impact is devastating, as attackers may be able to access the millions of private AI models and apps stored within AI-as-a-service providers.”
The development comes as machine learning pipelines have emerged as a brand new supply chain attack vector, with repositories like Hugging Face becoming an attractive target for staging adversarial attacks designed to glean sensitive information and access target environments.
The threats are two-pronged, arising as a result of shared Inference infrastructure takeover and shared CI/CD takeover. They make it possible to run untrusted models uploaded to the service in pickle format and take over the CI/CD pipeline to perform a supply chain attack.
The findings from the cloud security firm show that it’s possible to breach the service running the custom models by uploading a rogue model and leverage container escape techniques to break out from its own tenant and compromise the entire service, effectively enabling threat actors to obtain cross-tenant access to other customers’ models stored and run in Hugging Face.

“Hugging Face will still let the user infer the uploaded Pickle-based model on the platform’s infrastructure, even when deemed dangerous,” the researchers elaborated.
This essentially permits an attacker to craft a PyTorch (Pickle) model with arbitrary code execution capabilities upon loading and chain it with misconfigurations in the Amazon Elastic Kubernetes Service (EKS) to obtain elevated privileges and laterally move within the cluster.
“The secrets we obtained could have had a significant impact on the platform if they were in the hands of a malicious actor,” the researchers said. “Secrets within shared environments may often lead to cross-tenant access and sensitive data leakage.
To mitigate the issue, it’s recommended to enable IMDSv2 with Hop Limit so as to prevent pods from accessing the Instance Metadata Service (IMDS) and obtaining the role of a Node within the cluster.
The research also found that it’s possible to achieve remote code execution via a specially crafted Dockerfile when running an application on the Hugging Face Spaces service, and use it to pull and push (i.e., overwrite) all the images that are available on an internal container registry.
Hugging Face, in coordinated disclosure, said it has addressed all the identified issues. It’s also urging users to employ models only from trusted sources, enable multi-factor authentication (MFA), and refrain from using pickle files in production environments.
“This research demonstrates that utilizing untrusted AI models (especially Pickle-based ones) could result in serious security consequences,” the researchers said. “Furthermore, if you intend to let users utilize untrusted AI models in your environment, it is extremely important to ensure that they are running in a sandboxed environment.”
The disclosure follows another research from Lasso Security that it’s possible for generative AI models like OpenAI ChatGPT and Google Gemini to distribute malicious (and non-existant) code packages to unsuspecting software developers.

In other words, the idea is to find a recommendation for an unpublished package and publish a trojanized package in its place in order to propagate the malware. The phenomenon of AI package hallucinations underscores the need for exercising caution when relying on large language models (LLMs) for coding solutions.
AI company Anthropic, for its part, has also detailed a new method called “many-shot jailbreaking” that can be used to bypass safety protections built into LLMs to produce responses to potentially harmful queries by taking advantage of the models’ context window.
“The ability to input increasingly-large amounts of information has obvious advantages for LLM users, but it also comes with risks: vulnerabilities to jailbreaks that exploit the longer context window,” the company said earlier this week.
The technique, in a nutshell, involves introducing a large number of faux dialogues between a human and an AI assistant within a single prompt for the LLM in an attempt to “steer model behavior” and respond to queries that it wouldn’t otherwise (e.g., “How do I build a bomb?”).